
티스토리 뷰
개요
- 깨끗한 음성 통화 지원을 위해 WebRTC의 Noise Suppression 기능을 개선한다.
- RNN (Recurrent Neural Network) 적용 모델을 사용한다.
- RNN은 음성 및 노이즈와 같이 Sequence 하게 들어오는 데이터에 적합한 구조이다.
- 아래 Open source를 활용한다.
- Open Source
- RNN의 일종인 GRU(Gated Recurrent Units) 가 적용되어 있다.
- https://jmvalin.ca/demo/rnnoise/
- github: https://github.com/xiph/rnnoise
- Open Source
과정
- 노이즈만 있는 데이터와 클린한 음성 데이터를 다운로드 한다.
- 다운 받은 노이즈 파일과 클린한 음성 데이터를 WebRTC 스펙에 맞게 전처리 해준다.
- 전처리된 노이즈 데이터와 클린한 음성데이터를 가지고 학습을 진행한다.
- rnnoise demo를 이용하여 라이브콜 음원을 녹음하여 Denoise 전후를 비교해본다.
- 효과가 있으면, weight 값을 .c 파일과 .h 파일에 dump 한다. 효과가 없으면, 반성 후 뭐가 잘못 됐는 지 알아본 후 다시 시도해본다.
- dump 한 파일을 sdk 에 포팅한다.
- WebRtcAudioRecord.java 에 적용하여 동작 확인 및 rnnoise 전후를 비교한다.
데이터 다운로드
- 노이즈 데이터: https://media.xiph.org/rnnoise/rnnoise_contributions.tar.gz (6.4GB)
- 클린한 음성데이터: https://www.openslr.org/resources/40/zeroth_korean.tar.gz (10GB)
데이터 전처리 과정
데이터 전처리는 아래의 과정을 거친다.
- 오디오 스펙 변경
- 노이즈 파일은 48000Hz, Mono, Signed 16 bit PCM 이고,
- 클린한 음성 데이터는 16000Hz, Mono, Signed 16 bit FLAC이다.
- 클린한 음성 데이터의 경우, WebRTC 스펙인 48000, Mono, Signed 16 bit PCM 에 맞게 변환한다.
- 파일 합치기
- 각 데이터 파일은 여러개의 파일로 나뉘어져 있다.
- 학습을 위해 하나의 파일로 합쳐야 한다.
- 노이즈 데이터와 음성 데이터는 여러개 파일로 나뉘어져 있다. 학습에 사용하기 위해 하나의 파일로 합쳐야 한다.
- 하나로 합치기 위해 우선 모든 데이터 파일을 wav파일로 변환한다. ffmpeg을 이용한다.
- 여러개의 PCM 또는 FLAC 파일을 WAV파일로 변환하기 위해 아래와 같은 명령어를 사용한다.
> for i in ./*.pcm; do ffmpeg -i "$i" "../noise_wav/`basename -s .pcm $i`.wav"; done3. 오디오 파일을 하나로 합친다.
- sox 프로그램 사용 방법(sox은 wav 파일만 합칠 수 있지만, ffmpeg 보다 명령어가 간단해서 sox로 합침.)
> sox *.wav input.wav- ffmpeg 사용 방법
> ffmpeg -f concat -safe 0 -i <( for f in *.wav; do echo "file '$(pwd)/$f'"; done ) input.wav- WebRTC 스펙에 맞게 변환한다.
- ffmpeg을 사용하여 변환하는 방법.
> ffmpeg -i input.wav -ar 48000 output.wav- 그리고 나서 다시 WAV 파일을 PCM으로 변환한다.
- ffmpeg 사용 (PCM 16bit little ending, Sample Rate 48000Hz)
> ffmpeg -i output.wav -f s16le -ar 48000 -acodec pcm_s16le noise.raw- 데이터 전처리 과정을 마쳤다면, 이제 학습을 시작한다.
학습 과정
rnnoise source 에서 아래 과정으로 학습을 진행한다.
- 소스 컴파일
> cd src ; ./compile.sh- 노이즈 음원 및 클린한 음성 음원 학습

> ./denoise_training speech.raw noise.raw count > training.f32
(speech.raw -> 클린한 음성, noise.raw -> 노이즈)
(count 값은 데이터 양에 따라 500000 ~ 50000000 까지 입력할 수 있음. 여기서는 5000000을 입력함.)
(50000000 으로 입력하니까 컴터가 못견디고 Out of memory 발생함.)- 학습된 binary 파일을 keras에서 읽어올 수 있도록 h5 파일 형식으로 변환함.
> cd training; ./bin2hdf5.py ../src/training.f32 5000000 87 training.h5- 이어서 실질적인 학습 과정. (오래걸림. 내 컴퓨터 기준 13시간)
> ./rnn_train.py- 확습 완료 후 .c 파일과 .h 파일에 weight 값을 dump한다.
> ./dump_rnn.py weights.hdf5 ../src/rnn_data.c ../src/rnn_data orig
학습 결과를 통한 Denoise 작업
- 아래 명령어를 사용한다.
> cd rnnoise
To compile, just type:
> ./autogen.sh.
(패키지 추가로 필요할 수 있음. 아래 두 패키지를 설치한다.)
(sudo apt-get install autoconf; sudo apt-get install libtool)
> ./configure
> make
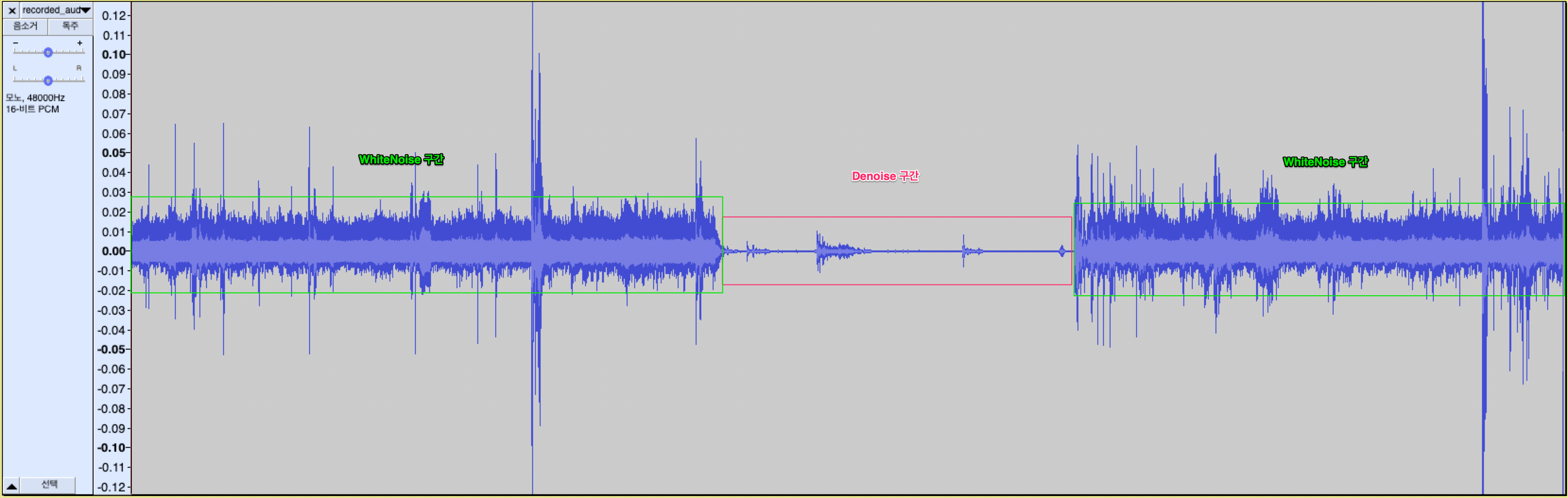
> ./examples/rnnoise_demo <noisy speech> <output denoised>- 동일한 음원으로 denoise한 결과를 파형으로 비교하였다. Denoise 한 결과 아래와 같이 잡음에 대한 파형이 줄어든 것을 확인할 수 있음.

3. rnn_data.c 파일 dump 완료
결과
WebRTC 음성의 White noise 부분 제거 확인.
RNNNoise 적용한 앱
CleanVoice - Google Play 앱
인공 지능 기반 소음 억제 레코더
play.google.com
'AI' 카테고리의 다른 글
| [프롬프트 엔지니어링] 1장. 생성형 AI, 진짜 똑똑한 걸까? (0) | 2025.05.30 |
|---|---|
| [AI] AI 음성 에이전트 (0) | 2023.01.31 |
| [환경구축] GTX 750 Ti, Ubuntu 18.04 (2) Anaconda, Tensorflow GPU (0) | 2022.12.19 |
| [환경구축] GTX 750 Ti, Ubuntu 18.04 (1) Nvidia driver, CUDA, cuDNN 설치 (0) | 2022.12.19 |
| [논문리뷰] LAS(Listen, Attend and Spell) (0) | 2022.04.26 |